“Nearly all of deep learning is powered by one very important algorithm: Stochastic Gradient Descent (SGD)” — Goodfellow.
Bạn đang xem: Phương pháp gradient tối ưu hóa
Trong nội dung bài viết này mình sẽ đề cập mang đến một thuật toán rất quan trọng cho các bài toán buổi tối ưu trong Machine Learning, Neural Network với Deep Learning mà bất kể Data Scientist, Computer Vision giỏi AI Engineer đều đề xuất biết, sẽ là Gradient Descent (GD). Đồng thời họ sẽ riêng biệt và làm rõ một số định nghĩa có liên quan tới GD thường xuất xắc lẫn lộn là Sample, Epoch, Batch và Iterations, cũng giống như một số vụ việc có liên quan tới GD.
Trước lúc đi vào mày mò về GD, họ cần hiểu cố nào là thuật toán về tối ưu (Optimization Algorithm) vào Artificial Neural Networks (ANN). Về cơ bản, các thuật toán buổi tối ưu đó là các engine cửa hàng để thành lập các quy mô neural network với phương châm là “học” được các điểm lưu ý (features xuất xắc patterns) từ dữ liệu đầu vào, tự đó hoàn toàn có thể tìm một tập những weights W cùng bias b (hay internal model parameters) để buổi tối ưu hóa độ đúng mực của models (obtaining a high accuracy models).
Nhưng vụ việc là “học” như thế nào? rõ ràng hơn là làm sao để kiếm tìm W với b một phương pháp hiệu quả! gồm phải chỉ cần random W với b một vài lần hữu hạn với “hy vọng” tại một bước như thế nào đó chúng ta sẽ tìm ra được tập lời giải. Rõ ràng là không khả thi và tiêu tốn lãng phí tài nguyên! chúng ta cần một thuật toán để nâng cao W cùng b theo mỗi bước (iterative improving), và đó là vì sao GD ra đời.
1. Gradient Descent là gì?Gradient Descent là một trong những thuật toán tối ưu lặp (iterative optimization algorithm) được sử dụng trong những bài toán Machine Learning cùng Deep Learning (thường là các bài toán buổi tối ưu lồi — Convex Optimization) với kim chỉ nam là tra cứu một tập những biến nội trên (internal parameters) cho việc tối ưu models. Trong đó:
● Gradient: là tỷ lệ độ nghiêng của con đường dốc (rate of inclination or declination of a slope). Về phương diện toán học, Gradient của một hàm số là đạo hàm của hàm số đó tương xứng với mỗi trở thành của hàm. Đối cùng với hàm số đối kháng biến, bọn họ sử dụng tư tưởng Derivative nạm cho Gradient.
● Descent: là tự viết tắt của descending, nghĩa là giảm dần.
Gradient Descent có tương đối nhiều dạng khác nhau như Stochastic Gradient Descent (SGD), Mini-batch SDG. Dẫu vậy về cơ bạn dạng thì hầu hết được thực thi như sau:
Khởi tạo đổi mới nội tại.Đánh giá chỉ model dựa vào biến nội tại và hàm mất đuối (Loss function).Cập nhật các biến nội tại theo phía tối ưu hàm mất non (finding optimal points).Lặp lại bước 2, 3 tính đến khi thỏa đk dừng.Công thức update cho GD có thể được viết là:
trong kia θ là tập những biến cần cập nhật, η là tốc độ học (learning rate), ▽Өf(θ) là Gradient của hàm mất đuối f theo tập θ.
Gradient Descent rất có thể được minh họa như vào hình:
Tối ưu hàm mất mát là việc tìm và đào bới các điểm optimal points cơ mà ở kia hàm mất non đạt cực lớn (maximum) hoặc cực tiểu (minimum). Nếu như hàm mất mát chưa hẳn là hàm lồi thì sẽ sở hữu các local maximum hoặc local minimum points bên cạnh các global maximum hoặc global minimum points như hình bên dưới. Mục tiêu của GD là tìm được các global minimum points. Mặc dù trong những bài toán buổi tối ưu lồi vận dụng GD thì các local minimum points của hàm mất non cũng đó là global minimum points của nó.
Điều kiện giới hạn của GD hoàn toàn có thể là:
● xong tất cả các epochs đã được định sẵn.
● cực hiếm của hàm mất mát đủ bé dại và độ đúng mực của mã sản phẩm đủ lớn.
● Hàm mất mát có mức giá trị không thay đổi sau một vài lần hữu hạn epochs.
Các bài toán trong thực tiễn áp dụng GD thường xuyên khó kiếm được các global minimum points, phần nhiều rơi vào các local minimum points hoặc chưa phải các optimal points (not converging), tuy nhiên bọn họ vẫn gồm thể đồng ý các hiệu quả của GD trả về khi model đã đủ tốt (good enough).
“
Sample là 1 trong dòng dữ liệu bao hàm các inputs để mang vào thuật toán, một đầu ra (ground-truth) để so sánh với giá bán trị dự kiến và tính quý giá của hàm mất mát. Dữ liệu giảng dạy thường bao gồm nhiều samples. Sample có cách gọi khác là instance, an observation, an đầu vào vector, giỏi a feature vector.
2.2 EpochEpoch là một hyperparameter vào ANN, được dùng để làm định nghĩa số lần learning algorithm vận động trên model, một epoch xong là khi tất cả dữ liệu training được đưa vào mạng neural network một lần (đã bao hàm cả 2 bước forward với backward mang lại việc cập nhật internal mã sản phẩm parameters).
Tuy nhiên khi tài liệu training là quá lớn (ví dụ training images từ Image
Net, Google xuất hiện Images), việc đưa tất cả training data vào trong một epoch là không khả thi và không hiệu quả. Trường phù hợp số epoch bé dại thì dễ dàng dẫn cho underfitting vì mã sản phẩm không “học” được rất nhiều từ GD để update các đổi thay nội tại. Đối với những trường vừa lòng này thì phương án là chia bé dại training dataset ra thành các batches cho từng epoch thì thời cơ model học được từ GD sẽ nhiều hơn thế nữa và tốc độ đo lường và thống kê sẽ buổi tối ưu hơn.
Xem thêm: Thuyết trình về phong cách ăn mặc của giới trẻ hiện nay khiến bạn mê mẫn
Chọn số epoch như vậy nào? Thường bọn họ cần một trong những lượng khủng epoch nhằm training mang đến ANN (10, 100, 500, 1000…) tuy vậy cũng còn tùy thuộc vào vấn đề và tài nguyên máy tính. Một phương pháp khác là thực hiện Learning Curve để tìm số epoch.
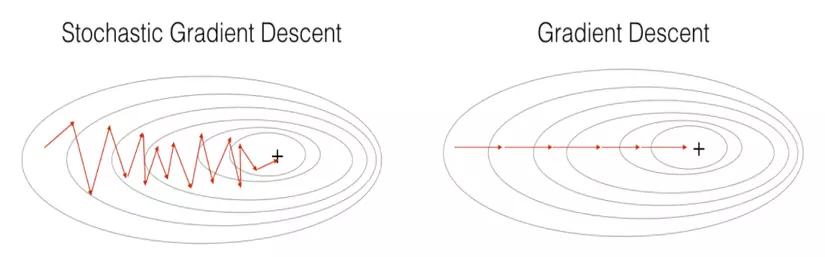
2.3 BatchNhư sẽ nói, một tập training dataset hoàn toàn có thể được chia nhỏ thành những batches (sets, parts). Một batch đang chứa những training samples, và con số các samples này được gọi là batch size. Cần chú ý có 2 khái niệm khác nhau là batch size và number of batches (số lượng những batches) or iterations. Tùy trực thuộc vào batch size nhưng mà GD sẽ sở hữu được các đổi thay thể khác nhau:
● Batch Gradient Descent: Batch size = kích thước of Training Dataset
● Stochastic Gradient Descent: Batch form size = 1
● Mini-Batch Gradient Descent: 1 2.4 Iterations
Iteration là số lượng batches (number of batches) cần thiết để chấm dứt một epoch. Công thức tính là iterations = training samples/batch size. Ví dụ: một dataset bao gồm 200 samples, lựa chọn batch size là 5, số epochs là 1000 thì trong 1 epoch số iterations sẽ là 200/5 = 40, mã sản phẩm sẽ tất cả cơ hội update các đổi thay nội trên 40 lần, nhân với số epochs thì số lần update của model sẽ là 40*1000 = 40000 lần (tương ứng với 40000 batches).
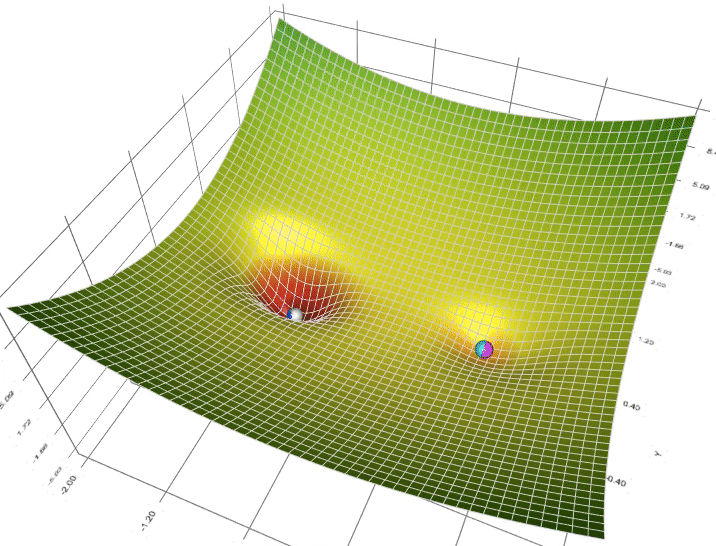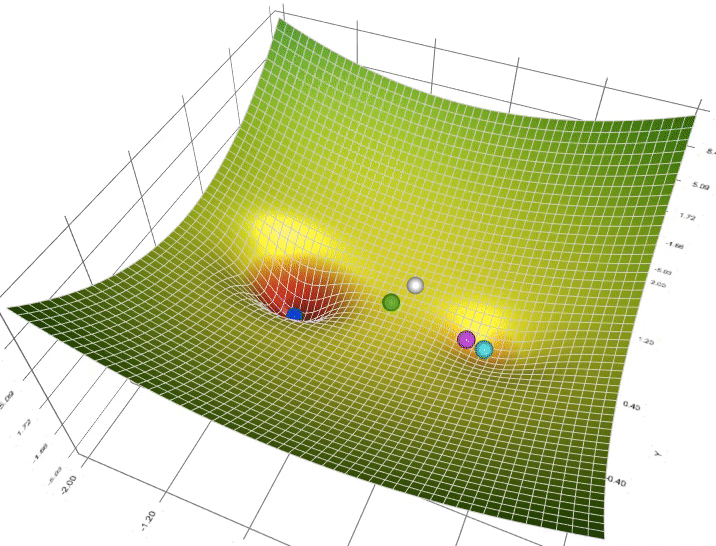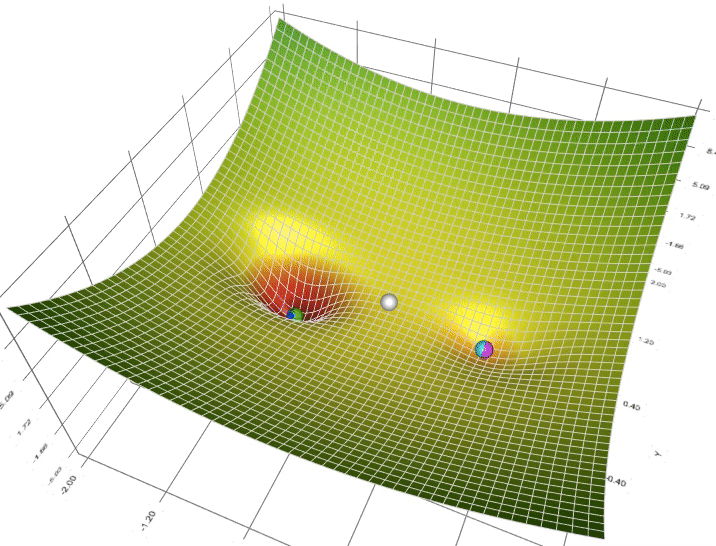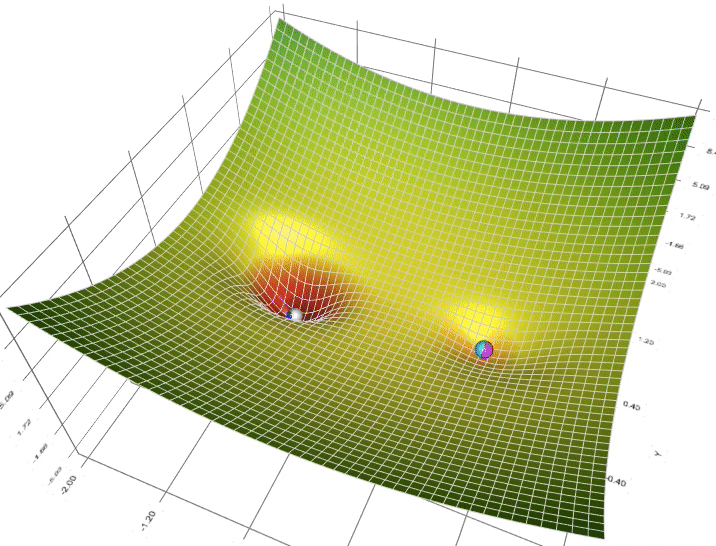
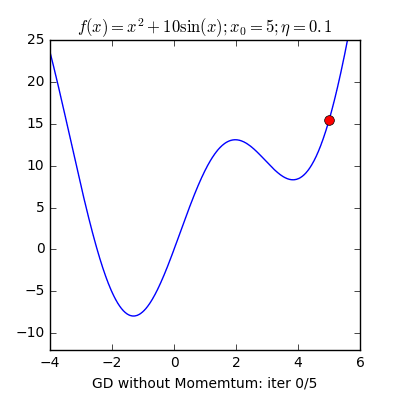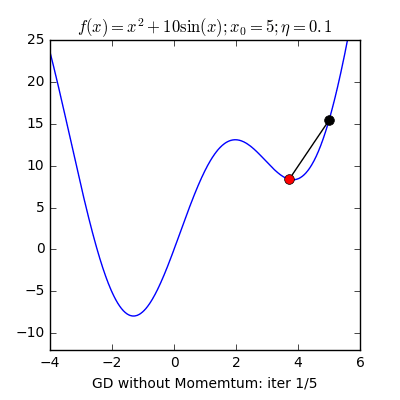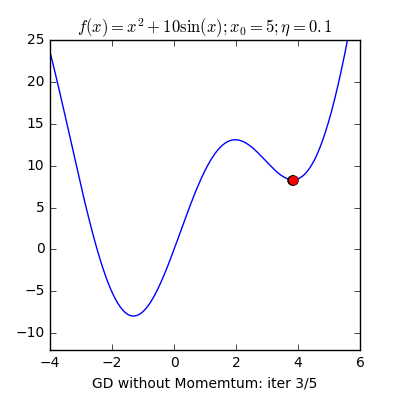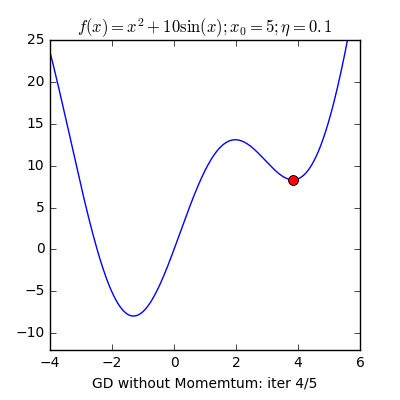
3. Một trong những vấn đề vào Gradient Descent3.1 Momentum với Nesterov’s AccelerationNhắc lại công thức cập nhật của GD, một thông số rất quan trọng cần quan tâm đến là vận tốc học η (learning rate), η sẽ nguyên lý số bước “học” quan trọng cho models. Việc chọn η phù hợp sẽ tùy thuộc vào mã sản phẩm và dataset. Giả dụ η quá nhỏ thì mã sản phẩm sẽ mất tương đối nhiều steps xuất xắc iterations nhằm tiến tới các điểm optimal points. Trường hợp η quá lớn thì biến update sẽ “nhảy” quanh (bounding around) các điểm optimal points với không hội tụ. Hoàn toàn có thể minh hoạt như vào hình:
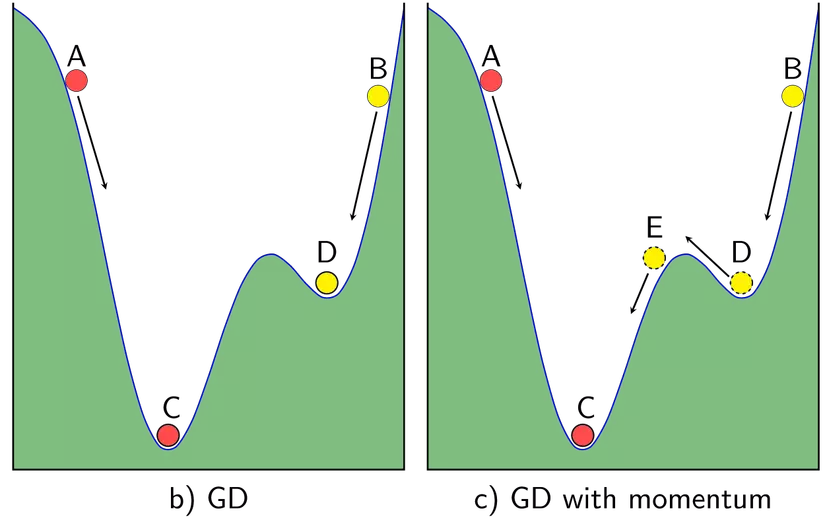
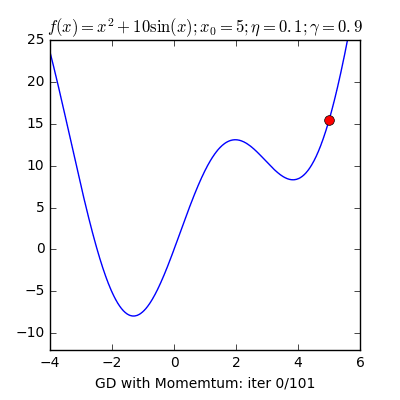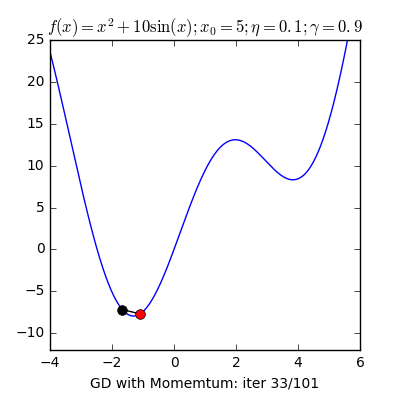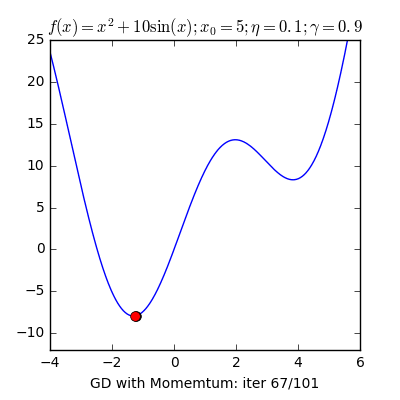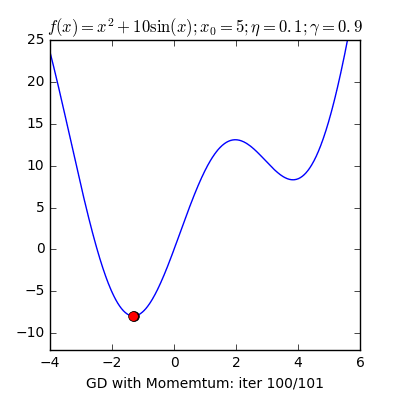
Sử dụng Momentum: ý tưởng cơ bạn dạng của momentum là gia tốc học khi cùng hướng cùng với chiều của gradient và tụt giảm học lúc ngược hướng với gradient. Khi momentum của GD đủ phệ thì những biến cập nhật có thể “vượt” qua các local optimal points để đào bới các điểm global như vào hình. Một tham số đặc biệt khi thực hiện momentum là γ, γ trong thực nghiệm hay được chọn là 0.9, hoặc thuở đầu chọn γ = 0.5 cho tới khi ổn định và tăng dần lên 0.9.
Net tốt Google mở cửa Images thì GD with momentum thường được sử dụng nhiều hơn nữa so cùng với Nesterov’s Acceleration. Còn đối với những dataset bé dại hơn thì chúng ta có thể sử dụng Nesterov’s Acceleration.
Thuật toán lan truyền ngược (Backpropagation Algorithm) là một thuật toán hay được thực hiện trong quá trình huấn luyện các mô hình học sâu. Ý tưởng cơ bạn dạng là thuật toán đang từ output đầu ra layer đi ngược quay lại input layer, giám sát và đo lường gradient của hàm mất mất tương xứng với những biến nội trên (weight, bias) cho những hidden layers rồi cần sử dụng GD để cập nhật lại những biến này. Thuật toán được mong mỏi đợi sẽ quy tụ sau một trong những lần hữu hạn epochs mà lại thường sẽ có sự tiến công đổi giữa độ đúng đắn của model và thời gian training.
Thực tế khi thực hiện training với backpropagation thì gradient của hàm mất mất sẽ bé dại dần do thực hiện nhân những số hạng nhỏ liên tiếp với nhau, nếu mô hình đủ “sâu” (nhiều hidden layers) thì quý hiếm gradient vẫn tiến dần đến 0 sau một trong những layers nhất quyết và làm cho cho mã sản phẩm không thể quy tụ -> ko thể update được các biến nội tại như mong muốn đợi. Hiện tượng lạ này gọi là Vanishing Gradient.
Tuy nhiên gradient cũng có chức năng lớn dần trong quy trình backpropagation (như mô hình RNNs) bởi nhân những số hạng lớn liên tục nhau dẫn tới những giá trị cập nhật quá lớn và cũng có tác dụng cho model không thể quy tụ (bounding around). Hiện tượng kỳ lạ này hotline là Exploding Gradient.
Có 2 lý do chính dẫn tới những hiện tượng trên là do việc khởi tạo các biến nội tại (weight initialization) và câu hỏi chọn activation function cho những layers. Có tương đối nhiều kỹ thuật khác biệt để giảm thiểu 2 hiện tượng lạ này như Xavier and He Initialization Techniques, Nonsaturating Activation Functions, Batch Normalization và Gradient Clipping.
3.3 Regularization“Many strategies used in machine learning are explicitly designed to lớn reduce the demo error, possibly at the expense of increased training error. These strategies are collectively known as regularization.” — Goodfellow
Regularization được dùng làm điều chỉnh tài năng “học” của model để đảm bảo rằng mã sản phẩm của chúng ta đủ tốt để lấy ra dự đoán cho các dữ liệu bắt đầu (control the ability to generalize). Nếu như không sử dụng regularization thì model rất dễ trở nên tinh vi (complex) và overfitting training data và chính vì thế không có tác dụng tổng quan liêu hóa cho tài liệu mới. Nhưng mà nếu sử dụng rất nhiều regularization thì mã sản phẩm sẽ trở nên đơn giản (simple) cùng không “học” được rất nhiều từ tài liệu training.
Trong vượt trình cập nhật biến của GD, regularization thường được cùng vào hàm mất mất bên dưới dạng L1 regularization, L2 regularization (còn hotline là weight decay) hoặc Elastic Net để triển khai cho các giá trị trong weights matrix không quá lớn, cho nên sẽ hạn chế khả năng bị overfitting của model. Ngoài ra còn có các kỹ thuật regularization khác ví như dropout, data augmentation và early stopping.
ConclusionTrong bài viết này mình đã reviews cho các bạn về Gradient Descent — thuật toán tối ưu rất đặc biệt dùng trong các quy mô học sâu. Đây là nền tảng gốc rễ để các bạn cũng có thể hiểu thêm về các thuật toán tối ưu khác như Ada
Grad, Ada
Delta, RMSProp, Adam. Đồng thời họ đã làm rõ một số khái niệm cũng như một số sự việc có tương quan tới GD. Với những kỹ năng này mình tin tưởng rằng các các bạn sẽ đủ từ tin để triển khai việc trên các quy mô học sâu về sau! Happy Learning!
https://towardsdatascience.com/epoch-vs-iterations-vs-batch-size-4dfb9c7ce9c9
https://machinelearningmastery.com/difference-between-a-batch-and-an-epoch/
https://machinelearningmastery.com/gradient-descent-for-machine-learning/
https://medium.com/onfido-tech/machine-learning-101-be2e0a86c96a
https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent
https://cs231n.github.io/neural-networks-3/
https://www.jeremyjordan.me/nn-learning-rate/
https://towardsdatascience.com/types-of-optimization-algorithms-used-in-neural-networks-and-ways-to-optimize-gradient-95ae5d39529f
https://towardsdatascience.com/demystifying-optimizations-for-machine-learning-c6c6405d3eea
https://www.quora.com/What-is-the-local-minimum-and-global-minimum-in-machine-learning-Why-are-these-important-in-machine-learning
Adrian Rosebrock (2017). Deep Learning for Computer Vision with Python. Starter Bundle: Py
Image
Search.com
Aurélien Géron (2017). Hands-On Machine Learning with Scikit-Learn & Tensor
Flow. Sebastopol: O’Reilly Media.
Chào các bạn, lúc này mình sẽ trình diễn về optimizer. Vậy optimizer là gì ?, nhằm trả lời câu hỏi đó thì chúng ta phải trả lời được các thắc mắc sau trên đây :
Các thuật toán buổi tối ưu, ưu nhược điểm của từng thuật toán, thuật toán buổi tối ưu này hơn thuật toán tê ở điểm như thế nào ?
Nội dung bài từ bây giờ mình sẽ giải thích chi tiết về optimizers theo tía cục trả lời các thắc mắc trên. Bài viết này sẽ không nặng về phần tính toán, code, mình sẽ sử dụng ví dụ trực quan để minh họa mang đến dễ hiểu.
Optimizer là gì, tại sao phải dùng nó?
Trước lúc đi sâu vào vấn đề thì chúng ta cần hiểu nỗ lực nào là thuật toán tối ưu (optimizers).Về cơ bản, thuật toán tối ưu là đại lý để xây dựng mô hình neural network với mục tiêu "học " được các features ( tuyệt pattern) của dữ liệu đầu vào, từ bỏ đó rất có thể tìm 1 cặp weights với bias cân xứng để về tối ưu hóa model. Nhưng vụ việc là "học" như vậy nào? cụ thể là weights với bias được tìm như thế nào! Đâu phải chỉ việc random (weights, bias) 1 số lần hữu hạn và hi vọng ở 1 bước nào kia ta hoàn toàn có thể tìm được lời giải. Cụ thể là không khả thi và lãng phí tài nguyên! họ phải tìm kiếm 1 thuật toán để nâng cao weight cùng bias theo từng bước, và đó là vì sao các thuật toán optimizer ra đời.
Các thuật toán buổi tối ưu ?
1. Gradient Descent (GD)
Trong những bài toán buổi tối ưu, bọn họ thường tìm giá chỉ trị nhỏ dại nhất của 1 hàm số nào đó, mà hàm số đạt giá trị nhỏ nhất lúc đạo hàm bằng 0. Nhưng đâu chỉ có lúc nào đạo hàm hàm số cũng được, đối với các hàm số nhiều trở thành thì đạo hàm rất phức tạp, thậm chí là là bất khả thi. Bắt buộc thay vào đó người ta search điểm gần với điểm rất tiểu nhất cùng xem sẽ là nghiệm bài bác toán.Gradient Descent dịch ra giờ đồng hồ Việt là giảm dần độ dốc, đề nghị hướng tiếp cận tại chỗ này là lựa chọn 1 nghiệm bất chợt cứ sau từng vòng lặp (hay epoch) thì đến nó tiến dần tới điểm cần tìm.Công thức : xnew = xold - learningrate.gradient(x) Đặt thắc mắc tại sao bao gồm công thức đó ? phương pháp trên được sản xuất để update lại nghiệm sau từng vòng lặp . Lốt "-" trừ tại đây ám chỉ ngược phía đạo hàm. Đặt tiếp câu hỏi tại sao lại ngược phía đạo hàm ?
Ví dụ như so với hàm f(x)= 2x +5sin(x) như hình bên dưới thì f"(x) =2x + 5cos(x)với x_old =-4 thì f"(-4) x_new > x_old nên nghiệm sẽ dịch rời về bên đề xuất tiến ngay gần tới điểm cực tiểu.ngược lại với x_old =4 thì f"(4) >0 => x_new a) Gradient cho hàm 1 biến đổi :
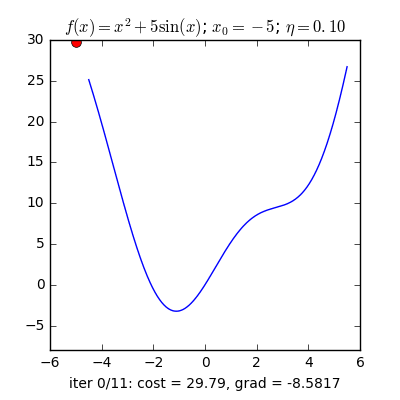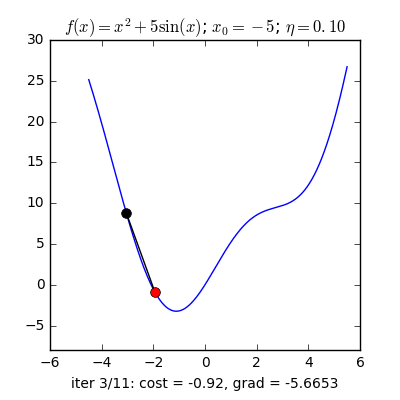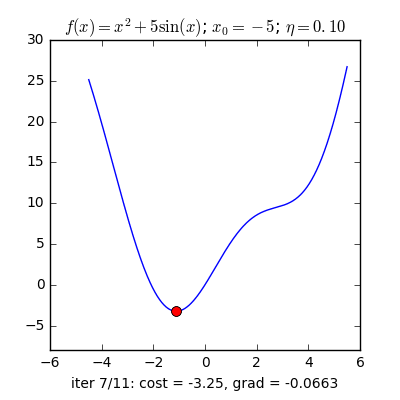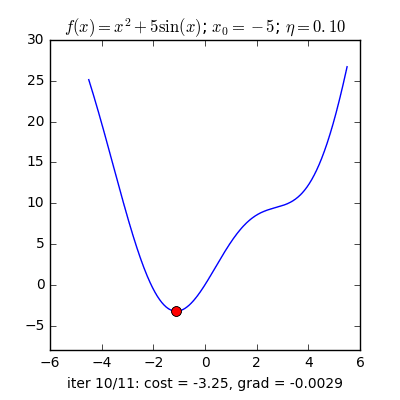
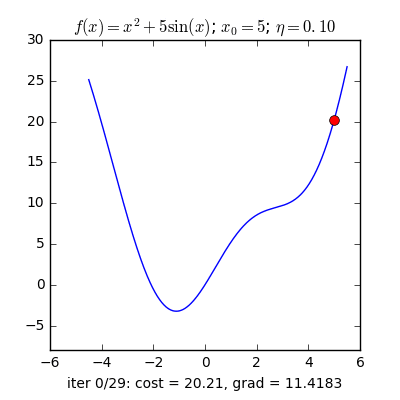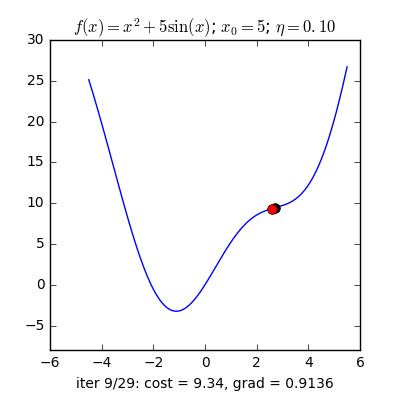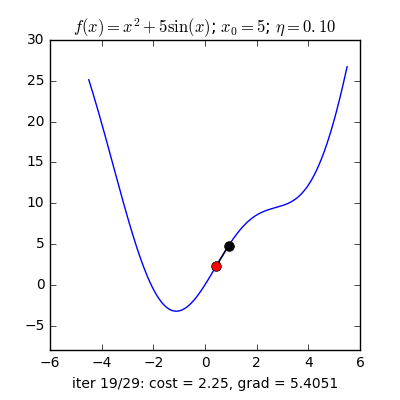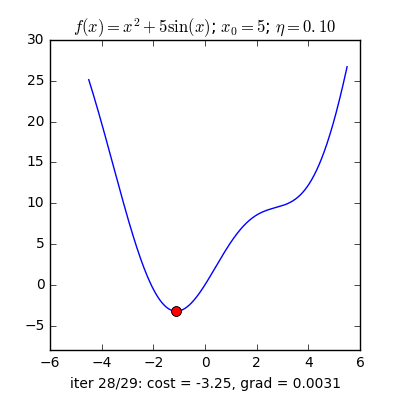
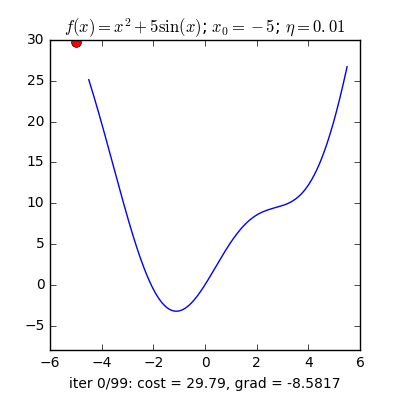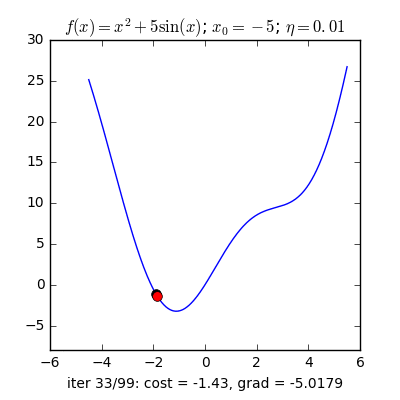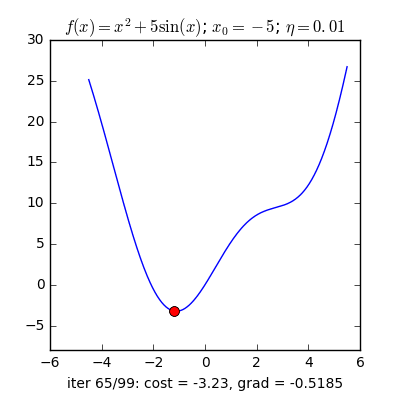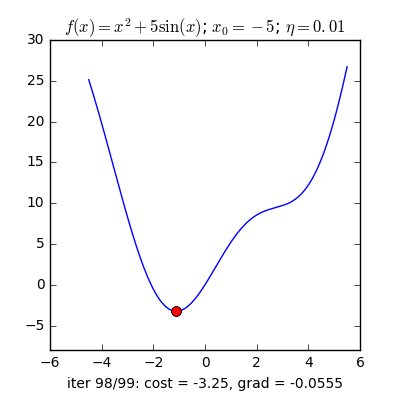
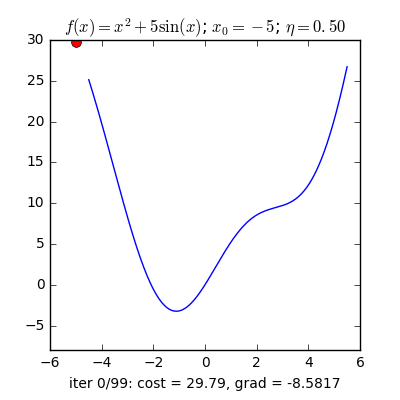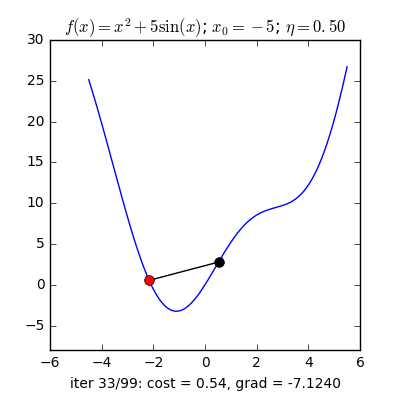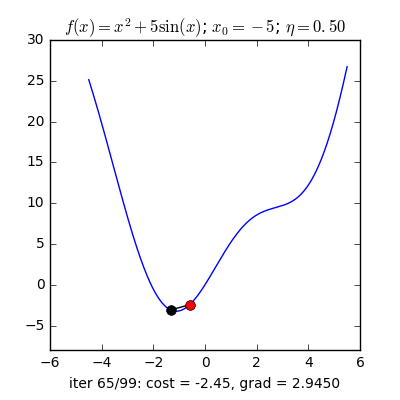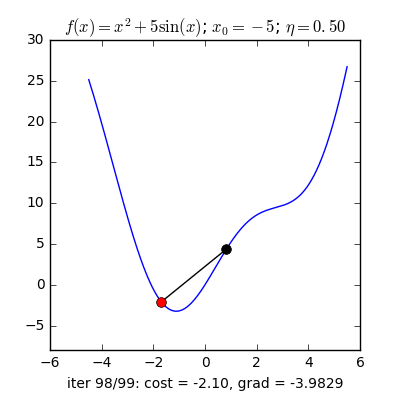
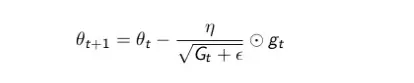
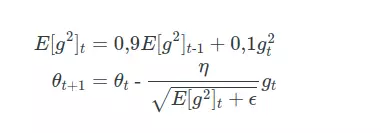
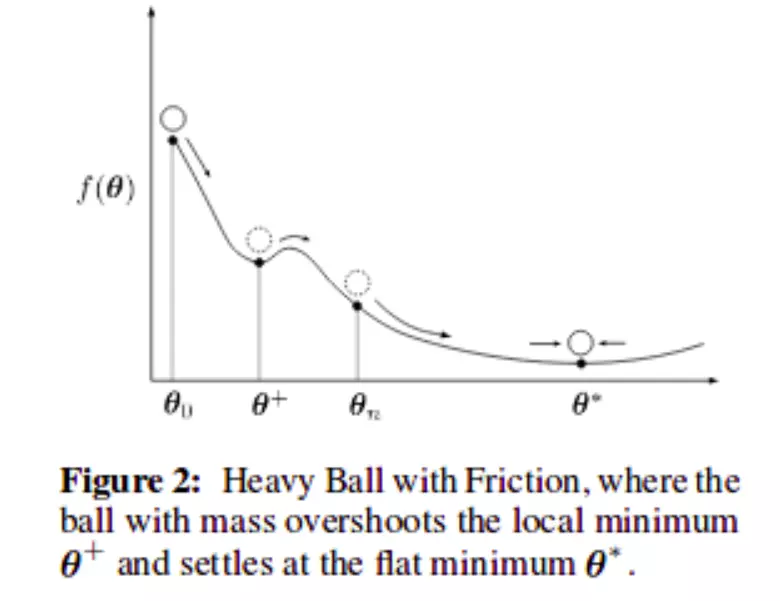
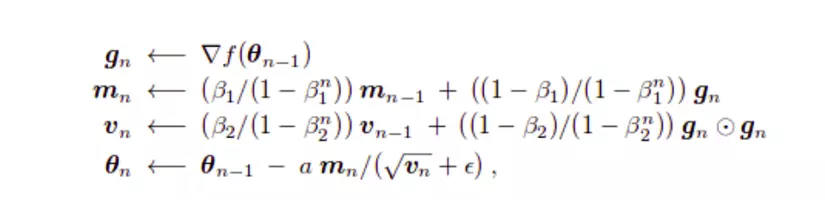
Tổng quan
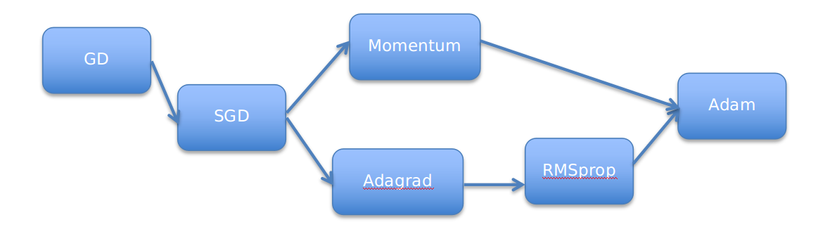
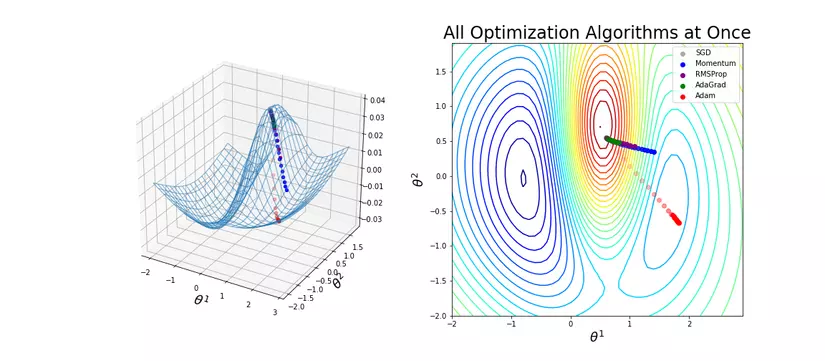
Còn có không ít thuật toán buổi tối ưu như Nesterov (NAG), Adadelta, Nadam,... Cơ mà mình đang không trình bày trong bài xích này, bản thân chỉ triệu tập vào những optimizers giỏi được sử dụng. Hiện giờ optimizers hay sử dụng nhất là "Adam".









{kind=link}